CPU utilization (or CPU %) is a ubiquitous metric and available as a first order metric in every modern OS.
Windows has the Task Manager, macOS the Activity Monitor and Linux has no standard, but top is probably the
most known tool to show CPU utilization..
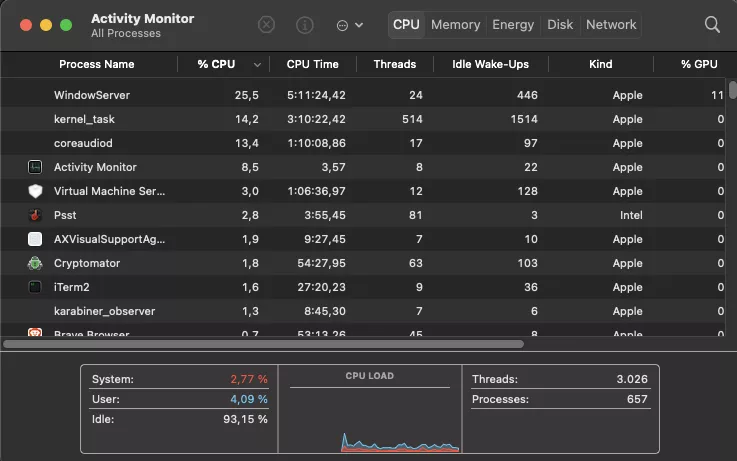
Activity Monitor under macOS showing CPU % in the first column
When conducting Green Coding analysis, our preference typically leans towards directly examining the energy metrics of components, if available. An example of this would be Intel’s RAPL, which we discuss in more detail here). However, in numerous contexts such as cloud computing, these metrics are not readily accessible."
Cloud services predominantly operate on Linux systems. However, cloud vendors only grant access to a subset of the values typically logged by a standard Linux OS. Notably, CPU utilization is often among the metrics that are readily available.
In this article, we aim to delve deeper into how CPU utilization is calculated in the Linux OS, and explore its usefulness as a metric for making assumptions about energy consumption and performance.
What do we want to find out?
Research question
How is CPU utilization defined and generated and how useful is it for energy and performance assumptions?
What is CPU utilization
CPU utilization is defined as the ratio of the total current utilization of a CPU over the total possible utilization
of a CPU.
Therefore, we begin with the following simple formula:
CPU % = CPU_work / CPU_total
All operating systems, that we know of, define the CPU_ variables through a unit of time. It is the time the processor
was doing any work (aka some instructions) or being in an idle state (aka not being assigned to process).
The concept of an idle state here is slightly different from the idle state in a processor (aka being halted).
An OS will typically also issue a HLT instruction when there is no process the scheduler needs to assign the processor to, but it should not be taken as guaranteed. Another wording that is often used is: “The CPU is put on the idle thread.”. This originates from the fact that usually at least one thread must be running to keep the scheduler working.
Also if you feed a process NOP instructions this would not count as idle for the operating system.
Now we are looking further where Linux gets this metric from, and by looking in the source code for top we find
that the values are captured from the procfs. More specifically system wide they come from /proc/stat.
If we now do a man proc on Linux we get the man page that tells us what the numbers that follow the CPU id mean:
user (1) Time spent in user mode.
nice (2) Time spent in user mode with low priority (nice).
system (3) Time spent in system mode.
idle (4) Time spent in the idle task. This value should be USER_HZ times the
second entry in the /proc/uptime pseudo-file.
iowait (since Linux 2.5.41)
(5) Time waiting for I/O to complete. This value is not reliable, for the
following reasons:
1. The CPU will not wait for I/O to complete; iowait is the time that a
task is waiting for I/O to complete. When a CPU goes into idle state
for outstanding task I/O, another task will be scheduled on this CPU.
2. On a multi-core CPU, the task waiting for I/O to complete is not running
on any CPU, so the iowait of each CPU is difficult to calculate.
3. The value in this field may decrease in certain conditions.
irq (since Linux 2.6.0)
(6) Time servicing interrupts.
softirq (since Linux 2.6.0)
(7) Time servicing softirqs.
steal (since Linux 2.6.11)
(8) Stolen time, which is the time spent in other operating systems when
running in a virtualized environment
guest (since Linux 2.6.24)
(9) Time spent running a virtual CPU for guest operating systems under the
control of the Linux kernel.
guest_nice (since Linux 2.6.33)
(10) Time spent running a niced guest (virtual CPU for guest operating sys‐
tems under the control of the Linux kernel).
We see now that our initial formula of CPU % = CPU_work / CPU_total was a bit too simple and modern
operating systems collect more granular metrics.
For Linux the actual implementation how for instance htop, which is similar to top, reports the CPU utilization is:
All these values in the /proc/stat file are of the unit jiffies. This means it is a proxy for the actual time
spent in that state. To get exact values we would need to multiply the jiffies with the USER_HZ variable of the
operating system.
If we just want to get the ratio though this step can be omitted.
We conclude that we now know where the CPU utilization comes from and that the resulting unit is a ratio of time.
Problems with CPU utilization
Now that we know how the value is defined we could argue that by for instance knowing that a system has a CPU utilization
of 20% we would know that we could still do 4 times more of the same calculations before we hit the 100%.
Or we could argue that 40% CPU utilization is double the amount of 20% cpu utilization.
Or, finally, if we know how much a CPU is consuming in terms of energy for 20% we would know that it would consume double that amount of energy if it would be on 40% utilization.
The most fundamental assumption here is that the average service time is constant, and does not depend upon the load level. This is one of the assumptions that has been broken by virtualization, Hyper-threading and variable speed power-saving CPUs.
The article presents many challenges like:
Hypervisors not fully mapping CPU to a guest which results in incomplete data
Hyper-Threading which creates “slow” cores and “fast” cores with the former being strongly non-linear in performance
CPU frequency changes over time
Especially the latter we want to look at into a bit more detail.
The jiffies metric in an operating system is usually based on the cycles, but can also be based on a monotonic timer.
In the former case our system will over-report the utilization if the CPU frequency is currently in a lower state
as the total elapsed cycles are not the maximum possible.
If the OS uses a monotonic timer which should be at the maximum cycle amount of the CPUs then we can use the counter
directly to reason about the CPU utilization. However this is usually not the case.
Example
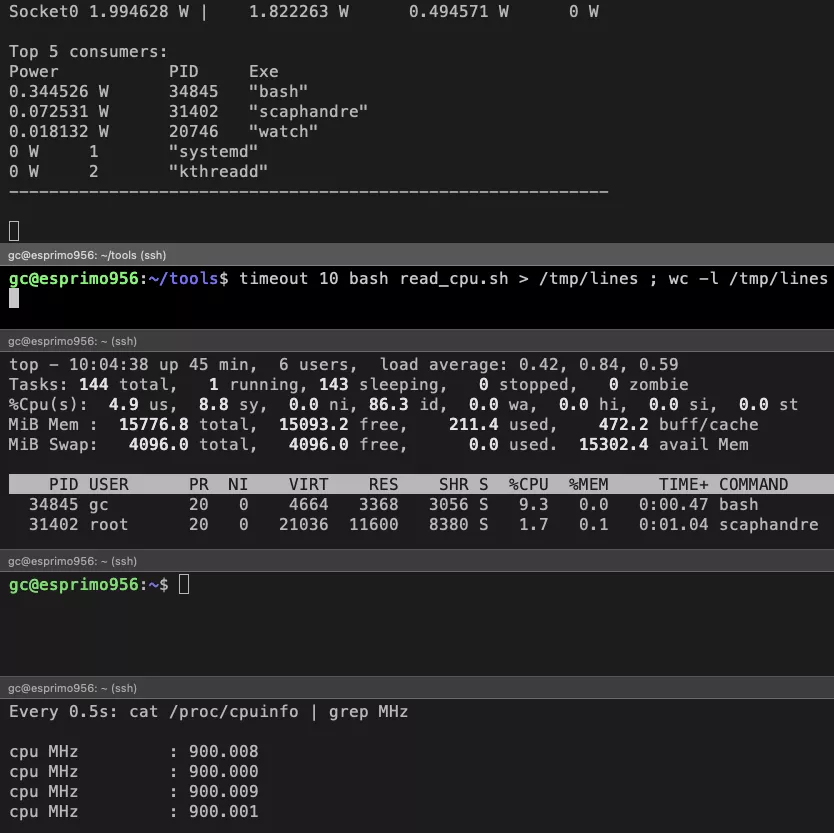
So taking a normal Ubuntu 22.04 system on a Fujitsu Esprimo 9564-Core machine we conduct the following test:
Run a simple program that calculates CPU utilization and outputs a line every 10 ms to a file and sleeps in between
Check how many lines were written
check top while doing so and write down the CPU utilization of the system as well as the process
check the frequency of all our cores on the system
Repeat the test couple of times to check if values are stable
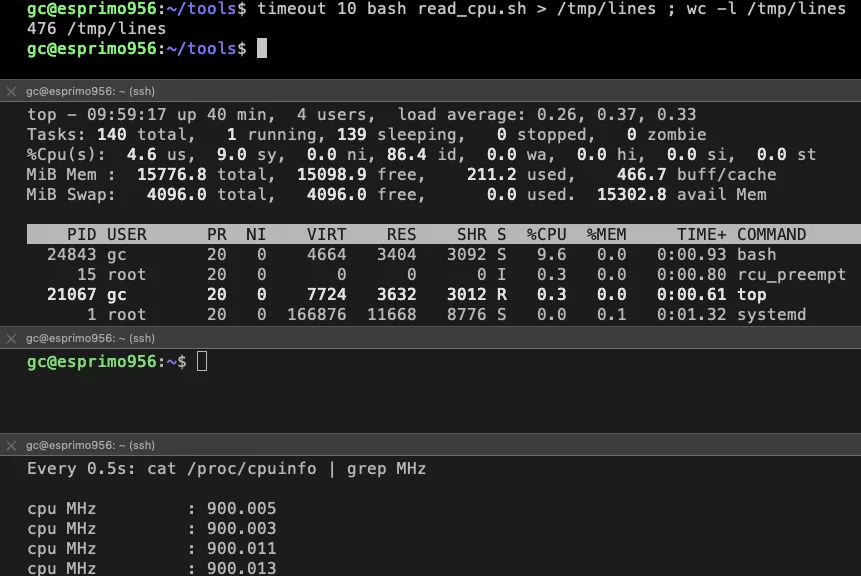
Dynamic CPU utilization low load
What we see here is that the CPU utilization for our sample program, which shows up as a bash, when there is no other load on the
system clocks in at 9.6% on a single core. This equals to 2.4% on the total 4-core system.
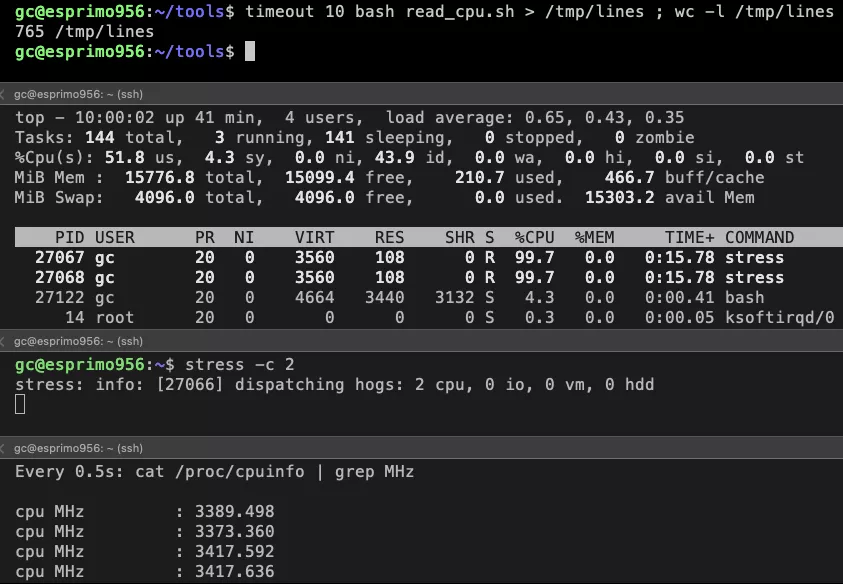
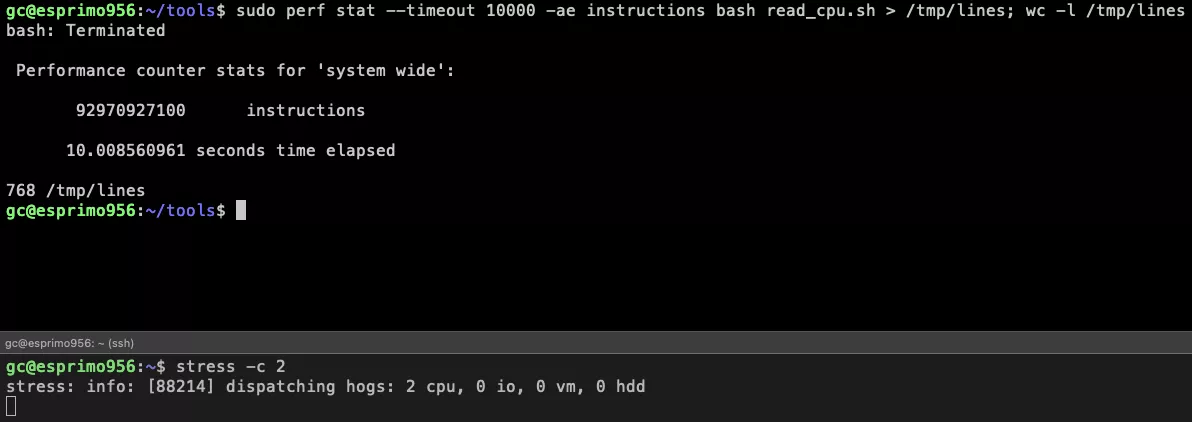
Now we introduce some load with running a stress process on two cores keeping these cores fully busy.
Dynamic CPU utilization high load
We see that the system wide CPU utilization climbs up to ~50% but the ratio attributed for the process now is at
4.3%.
This effect is nicely visualized here on a process level but the same issue happens with the system wide CPU utilization.
Most suprisingly: The throughput of the program has actually gone up! From 476 lines before to now 765 lines.
This behaviour comes from the fact that the CPU cycle count goes up and the process can actually do more work in the
same time.
The throughput is not linear and 100% is not double of 50%.
But even if we are in a non-virtualized, non-hyper-threaded and fixed-frequency environment CPU utilization can still
bite us if the CPU experiences memory congestion.
A stalling time due to memory I/O is then falsely attributed to a non-idle state. Details are in Brendan Gregg’s Blog - CPU Utilization is Wrong
Looking at energy in particular
We will now look at three ways how to use utilization in a system to get some energy values per process and how they differ.
CPU utilization through Scaphandre
First we use Scaphandre to get a first glimpse on an idle system.
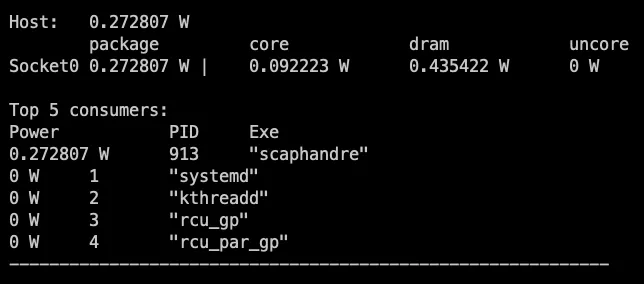
Scaphandre on an idle system
What we see is that the power that is reported by Intel RAPL, which is what Scaphandre reads, is fully attributed
to any process load that is found on the system.
This is a bit confusing at first, as the system also has an idle load … so, as discussed earlier, if the scheduler
puts cores on the idle thread they still consume energy, which will be reported by RAPL, but assinging them to a very
low load process that might not even be on the core sounds counter-intuitive.
This is also not documented on that form, but we assume it is a voluntary design decision.
It also feels like it, because otherwise Scaphandre would have to calculate the idle load on the sytem first, but
it starts right away with giving out numbers.
Now we put some load on the system and see how Scaphandre reports:
top and Scaphandre low loadtop and Scaphandre high load
We see again the about same utilzation values for our bash process, and we see that Scaphandre
reports ~ 0.34 W when we just run the read_cpu.sh on the system and ~ 0.43 W when
the system is stressed with two other stress processes.
Also we see that the numbers that Scaphandre is reporting per process do not add up to the total Package Power.
The power consumption of Scaphandre itself also drops from 0.07 W to 0.05 W
CPU utilization through top
Now we try to re-calculate the same numbers from Scaphandre through looking at the CPU utilization that top reports
and then getting to the share of the power consumption. We will actually be using the data that you already see on
the images above.
On the stressed machine Scaphandre reports a 24.71 W power on the CPU package and top shows a 4.3% utilization one one core.
This equals a 4.3 % / 4 = 1.075 % utilization on the whole 4-core machine.
If we now multiply 24.71 W * 0.01075 we get 0.27 W
For the un-stressed machine where just the read_cpu.sh runs it follows: 1.99 W * (0.093 / 4) = 0.046 W
These values are strongly different from what Scaphandre reports. Especially when there is a higher idle time, as it
is in the unloaded case, these values strongly differ.
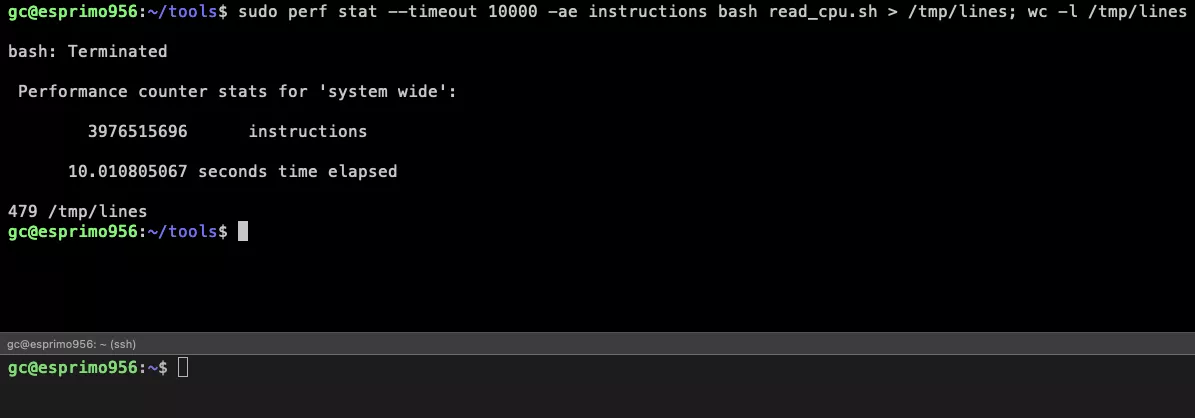
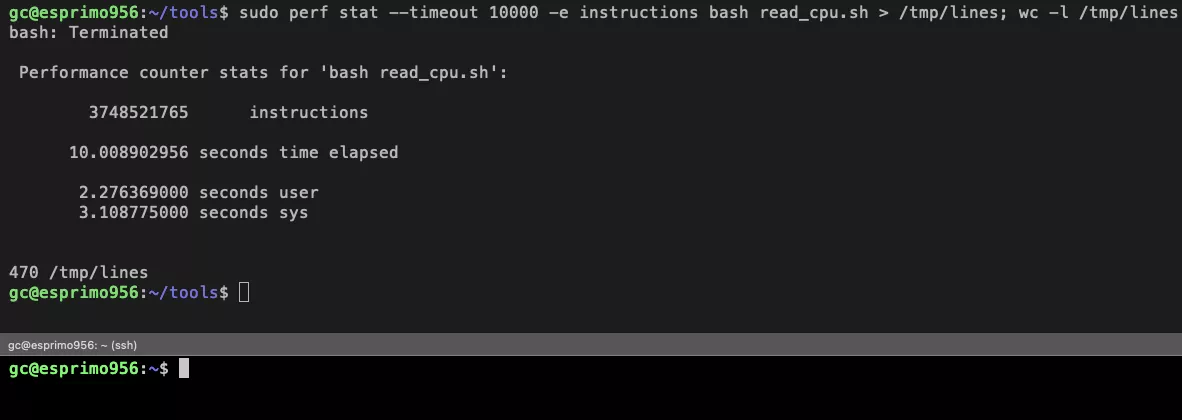
Instructions through perf
Let’s now make another approach though not using CPU utilization, but rather by using CPU instructions, which is the
same technique as for instance Kepler uses.
We will be running this command to geht the instructions for the process:
We make both calls once with stress running in the background and once without. All tests are repeated 10 times.
Since the energy loads on the system are quite identical, we will use the same energy values as in the Scaphandre case:
24.71 W for a loaded system and 1.99 W for an unloaded system where just the read_cpu.sh is running.
bash script unloaded with perf counting globallybash script unloaded with perf counting per processbash script loaded with perf counting globallybash script loaded with perf counting per process
Statistics for only read_cpu.sh running:
- 3748521765 Instructions read_cpu.sh (+/- 10%)
- 3976515696 Total System read_cpu.sh (+/- 10%)
- Ratio: 0.9426648985116944
- Runtime: 10s
=> 0.9426648985116944 * 1.99 W = 1.88 Joules => 1.88 J / 10 s = 0.19 W
Statistics on stressed system:
- 6102070028 Instructions read_cpu.sh (+/- 0.1%)
- 92970927100 Total System (+/- 0.1%)
- Ratio: 0.00400831162480985
- Runtime: 10s
=> 0.06563417423423758 * 24.71 W = 1.62 Joules => 1.62 J / 10 s = 0.16 W
Suprisingly we see that on an unloaded system the energy actually increases!
The assumption made here is that the cost per instruction goes down. This is an effect that can also be seen in
SPECPower benchmarks where the sweet-spot for a system is typically somewhere around the higher third quarter of the peak
performance.
Methodlogy
load
Power [W]
Scaphandre
loaded
0.43
CPU%
loaded
0.27
perf loaded
loaded
0.16
Scaphandre
unloaded
0.34
CPU%
unloaded
0.046
perf
unloaded
0.19
Can we somehow rescue CPU frequency?
What however would happen if we fix the CPU frequency, so that it is always running on the maximum frequency and do not utilize features such as Turbo Boost, Hyper Threading and not use virtualization?
The latter is probably a lost cause, as in basically every cloud machine and even shared hosting systems are virtualized.
We have here to rely on the fact that resources are not heavily oversubscribed and that hypervisors at least
report some correct values of the CPU registers needed to derive metrics like utilzation.
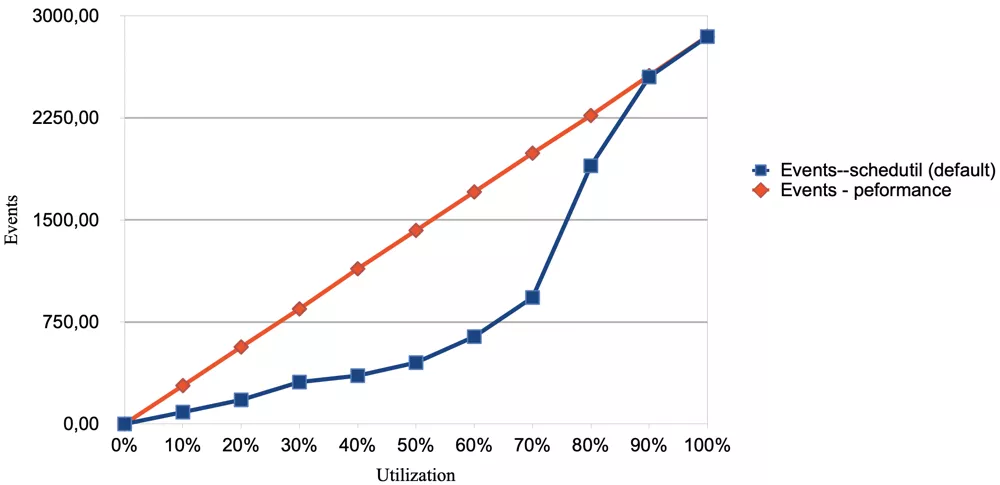
Because if we would have system that has a fixed CPU frequency the load-performance curve actually becomes linear:
Sysbench run on different stepswith CPU utilization
In this example we have run sysbench --cpu-max-prime=25000 --threads=1 --time=10 --test=cpu --events=0 --rate=0 and
put a CPU % limiting on the process and increased that in 10% increments.
The blue curve has been done with the schedutil CPU frequency govenor which dynamically scales the CPU frequency.
And the red curve has been done with the performance scaling govenor which scales the CPU frequency to a maximum as
soon as even a minimum amount of load happens on a core.
Let’s look at how different cloud vendors have this setting for CPU frequency and Turbo Boost set, so we can later
use that to make some assumptions on estimations models for the cloud:
Cloud
Frequency
Turbo Boost
Scaling Govenor
AWS EC2 m5.metal
dynamic
enabled
performance
AWS EC2 m5.large
dynamic
?
?
GITHUB ACTIONS (LINUX)
fixed
enabled
?
GITLAB PIPELINES (LINUX)
fixed
?
?
GOOGLE CLOUD (N2)
fixed
?
?
Hetzner
fixed
enabled
?
Here are the details, feel free to scroll to the bottom for the summary :)
AWS EC2 m5.metal (bare metal)
Frequency
We were running stress-ng -c 1 on one core to trigger different frequencies.
Every 2.0s: cat /proc/cpuinfo | grep MHz | uniq
cpu MHz : 2609.666
cpu MHz : 2500.000
cpu MHz : 3500.001
cpu MHz : 2500.000
CPU frequency is dynamic
P-States
....
core 95:
TurboBoost (MSR): enabled
scaling_governor: performance
scaling_driver: intel_pstate
energy_performance_preference: performance
CPU-wide settings
P_State status (off,active,passive): active
P_State no_turbo (0=allowed,1=off): 0
P_State max-turbo (%): 100
Available drivers for CPU DVFS:
performance powersave
CPUInfo
...
processor : 95
vendor_id : GenuineIntel
cpu family : 6
model : 85
model name : Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
stepping : 7
microcode : 0x5003303
cpu MHz : 2500.000
cache size : 36608 KB
physical id : 1
siblings : 48
core id : 29
cpu cores : 24
...
AWS EC2 m5.large (virtualized)
Frequency
Every 2.0s: cat /proc/cpuinfo | grep MHz | uniq
cpu MHz : 2499.998
cpu MHz : 3099.774
CPU frequency is dynamic
P-states
Reading this info is blocked by the hypervisor :(
CPUInfo
...
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 85
model name : Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
stepping : 7
microcode : 0x5003501
cpu MHz : 3097.292
cache size : 36608 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
...
Github Actions (Linux)
Frequency
Every 2.0s: cat /proc/cpuinfo | grep MHz | uniq
cpu MHz : 2793.437
cpu MHz : 2793.437
cat /proc/cpuinfo | grep MHz
cpu MHz : 2249.998
cpu MHz : 2249.998
CPU frequency does not change.
P-states
All info is blocked by the hypervisor :(
CPUInfo
...
processor : 1
vendor_id : AuthenticAMD
cpu family : 23
model : 49
model name : AMD EPYC 7B12
stepping : 0
microcode : 0xffffffff
cpu MHz : 2249.998
cache size : 512 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
...
Google Cloud (N2)
Frequency
cat /proc/cpuinfo | grep MHz
Every 2.0s: cat /proc/cpuinfo | grep MHz
cpu MHz : 2800.202
cpu MHz : 2800.202
cpu MHz : 2800.202
cpu MHz : 2800.202
cpu MHz : 2800.202
cpu MHz : 2800.202
cpu MHz : 2800.202
cpu MHz : 2800.202
CPU frequency does not change.
P-states
All info is blocked by the hypervisor :(
CPUInfo
...
processor : 7
vendor_id : GenuineIntel
cpu family : 6
model : 85
model name : Intel(R) Xeon(R) CPU @ 2.80GHz
stepping : 7
microcode : 0xffffffff
cpu MHz : 2800.202
cache size : 33792 KB
physical id : 0
siblings : 8
core id : 3
cpu cores : 4
...
Hetzner
Frequency
cat /proc/cpuinfo | grep MHz
Every 2.0s: cat /proc/cpuinfo | grep MHz
cpu MHz : 2294.606
CPU frequency does not change.
P-states
core 0:
TurboBoost (MSR): enabled
All other info is blocked by the hypervisor :(
CPUInfo
...
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 85
model name : Intel Xeon Processor (Skylake, IBRS)
stepping : 4
microcode : 0x1
cpu MHz : 2294.606
cache size : 16384 KB
physical id : 0
siblings : 1
core id : 0
cpu cores : 1
...
Summary
Over the course of the case study we have looked at how CPU utilization is defined generally and how it is implemented
in particular in the Linux operating systems.
We have seen that CPU utilization is by far no easily reproducible nor comparable metric and also not a linear metric.
Then we have looked at how energy can be split by this value and seen that it is highly tricky to use ratios for splitting.
The approach by Scaphandre is way better, by just using the elapsed jiffies but is at least of in the absolute
value from a harder metric like Instructions.
This makes CPU utilization really only helpful as an indicator internal to the same system.
These claims are only valid for machine CPU values, the value on a per process level is typically unusable for any
comparative or drill-down task.
Using this metrics to do any inference of other values is only feasible with a strongly and complex non-linear model
or if the system is configured in that way that many variables are fixed (like for instance Turbo Boost and CPU frequency).
As we have seen many cloud vendors, especially CI/CD tools like Github Actions or Gitlab Pipelines use
fixed frequency CPUs, which allow for making some reproducibility claims of the system performance and energy.
As said before, these are for instance the assumptions for our Cloud Energy model where we estimate the power draw of cloud machines based on the fact that in the SPECPower data we use there the systems have typically fixed C-States and P-States.
In a future piece we will look at how using CPU instructions and jiffies behaves on different load types.
We have here only compared a relatively small load process with a medium load system. However we assume that the ratio
will behave very differently for highly loaded systems and a high-load process.