You do not know about our Eco-CI project yet? Than read up here about it: Eco-CI project
Eco CI Energy Estimation Action
- by Dan Mateas 
As we mentioned in a previous blog article, we’ve been thinking of ways to make CI pipelines more energy efficient. One idea we had was to give developers a tool which allows them to measure the energy used by their CI runs.
After all, how can people reduce their carbon emissions if they don’t know how much energy they’re using in the first place? With that in mind we’re happy to announce a new Action which we’re publishing to the Github Actions marketplace: Eco CI Energy Estimation
This action measures the CPU used by the machine running your github VM and then uses our Cloud energy model to estimate the energy used by whichever sections of your workflow file you wish to measure. It is designed to be easily integrated into any workflow file you may already have with just a couple of calls. Let’s run through how to set up and use it.
The action has three tasks it can be invoked with: initialize, start-measurement, and get-measurement:
- uses: green-coding-solutions/eco-ci-energy-estimation@v1
with:
task: initialize
- uses: green-coding-solutions/eco-ci-energy-estimation@v1
with:
task: start-measurement
- uses: green-coding-solutions/eco-ci-energy-estimation@v1
with:
task: get-measurement
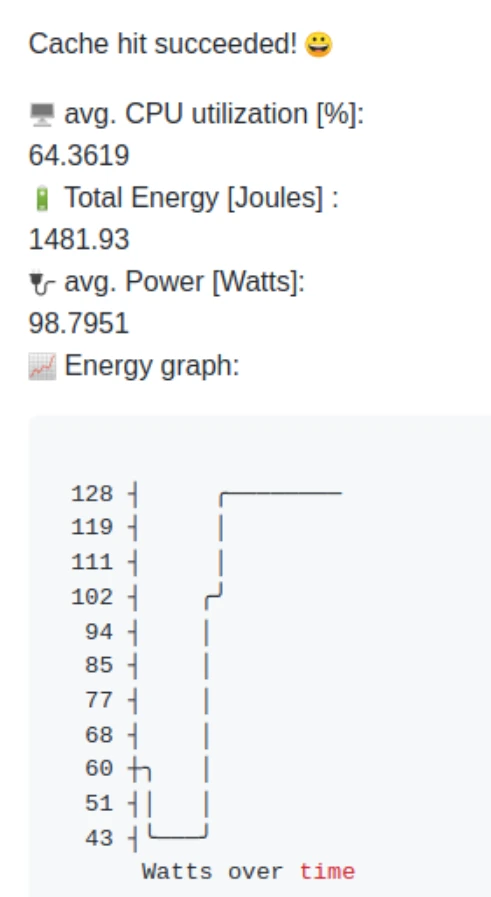
To begin, you must call the initialize task near the begining of your workflow. This will setup our machine learning model into the VM and all the necessary prerequisites. Then, you simply wrap start-measurement and get-measurement around the workload for which you want to estimate the energy of.
The start-measurement task begins to measure the CPU utilization from that moment onwards and save it to a temporary file. When you call get-measurement, it will note the measurement and feed that, along with any auto-detected relevant CPU information, into our machine learning model. Our model then outputs the estimated Energy used in Joules and avg. power in Watts to the Github Summary.
This estimation comes from data gathered from SPEC Power Database (hence the name). Further information about this model can be found in our blog post about the linear regression and blog post about the XGBoost implementation powering it.
Once you call the get-measurement task a second time, it will output the energy information to Github Summary a second time - and if you haven’t called start-measurement yet, this data will be cumulative.
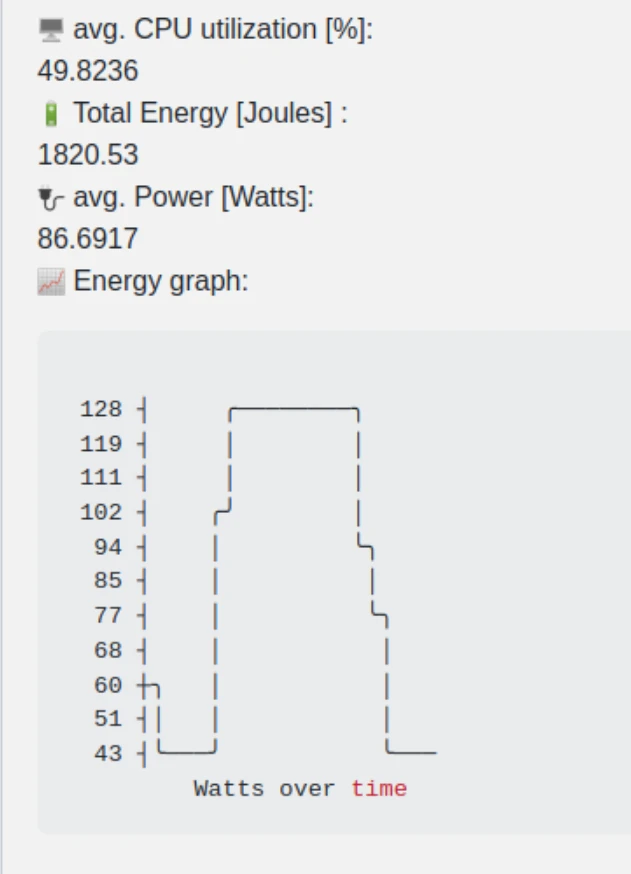
If you call start-measurement again, it will reset cpu utilization file. This way you can get discrete energy estimations for different sections of your workflow file.
Something to be aware of - many workflows will have different jobs. Each job spins up a different virtual machine which might be on a different phyiscal machine. This means that you need to call our action, including the initialize task, for each job.
We really hope that this tool will be used by developers to begin adding a level of energy awareness in their CI runs, without much hassle :-)